Aneesh Sathe
Jan. 5, 2025
January 5, 2025
Improving Research Through Safer Learning from Data #
Another one of Frank Harrell’s posts. Given my day job, and the R&D background this one is quite close to home. As a team leader on the industry side one hopes to build a culture with the team that aligns scientific rigor with company goals. Any method, statistical or cultural (in this case both), that solves for this tension will get you the most bang for your buck.
Building a startup, doing research, or even just launching a moonshot project is dependent on emergent actions and decisions. Behind this madness, there is a kind of Science of “Muddling Through” and Bayesian methods are perhaps best equipped:
make all the assumptions you want, but allow for departures from those assumptions. If the model contains a parameter for everything we know we don’t know (e.g., a parameter for the ratio of variances in a two-sample t-test), the resulting posterior distribution for the parameter of interest will be flatter, credible intervals wider, and confidence intervals wider. This makes them more likely to lead to the correct interpretation, and makes the result more likely to be reproducible.
In an environment of limited resources (time, money, investor patience), being able to quantify your data and obtaining bankable evidence is critical.
only the Bayesian approach allows insertion of skepticism at precisely the right point in the logic flow, one can think of a full Bayesian solution (prior + model) as a way to “get the model right”, taking the design and context into account, to obtain reliable scientific evidence.
The post provides a much more in-depth view, including an 8-fold path to enhancing the scientific process.
Why I walk #
Chris Arnade gives us a view into why he goes on insanely long (both distance and time) trips by foot and what he discovers there. I found this passage hilarious, in that money seems to converge on a version of living that is identical with different paint while the rich likely search for that unique way of living.
Every large global city has a few upscale neighborhoods that are effectively all the same. It is where the very rich have their apartments, the five and four star hotels are, the most famous museums, and a shopping district with the same stores you would find in Manhattan’s Upper East Side, or London’s Mayfair.
The only difference is the branding. So you get the Upper East Side with Turkish affectations, or a Peruvian themed Mayfair. The residents of these neighborhoods are also pretty comfortable in any global city. As long as it is the right neighborhood.
Having traveled a fair bit, the designation of tourist brings with it multiple horrors. Chris uses walking as a mini residing and side-steps much of it. :
Walking also changes how the city sees you, and consequently, how you see the city. As a pedestrian you are fully immersed in what is around you, literally one of the crowd. It allows for an anonymity, that if used right, breaks down barriers and expectations. It forces you to deal with and interact with things and people as a resident does. You’re another person going about your day, rather than a tourist looking to buy or be sold whatever stuff and image a place wants to sell you.
This particular experience reminded of the book Shantaram, a book about a foreigner being adsorbed to and absorbed by the local.
AI chatbots fail to diagnose patients by talking with them #
While interesting the research uses LLMs to play both patient and doctor. I like that there is research happening in this area and at least we are moving in the right direction with the testing of AI i.e. not just structured tests. I would perhaps not judge the “failure” too harshly as the source of the data as also an LLM and would suffer from deficiencies which an actual patient suffering from symptoms would not.
This paper introduces the Conversational Reasoning Assessment Framework for Testing in Medicine (CRAFT-MD) approach for evaluating clinical LLMs. Unlike traditional methods that rely on structured medical examinations, CRAFT-MD focuses on natural dialogues, using simulated artificial intelligence agents to interact with LLMs in a controlled environment.
While the paper has a negative result we do come away with a good set of recommendations for future evaluations.
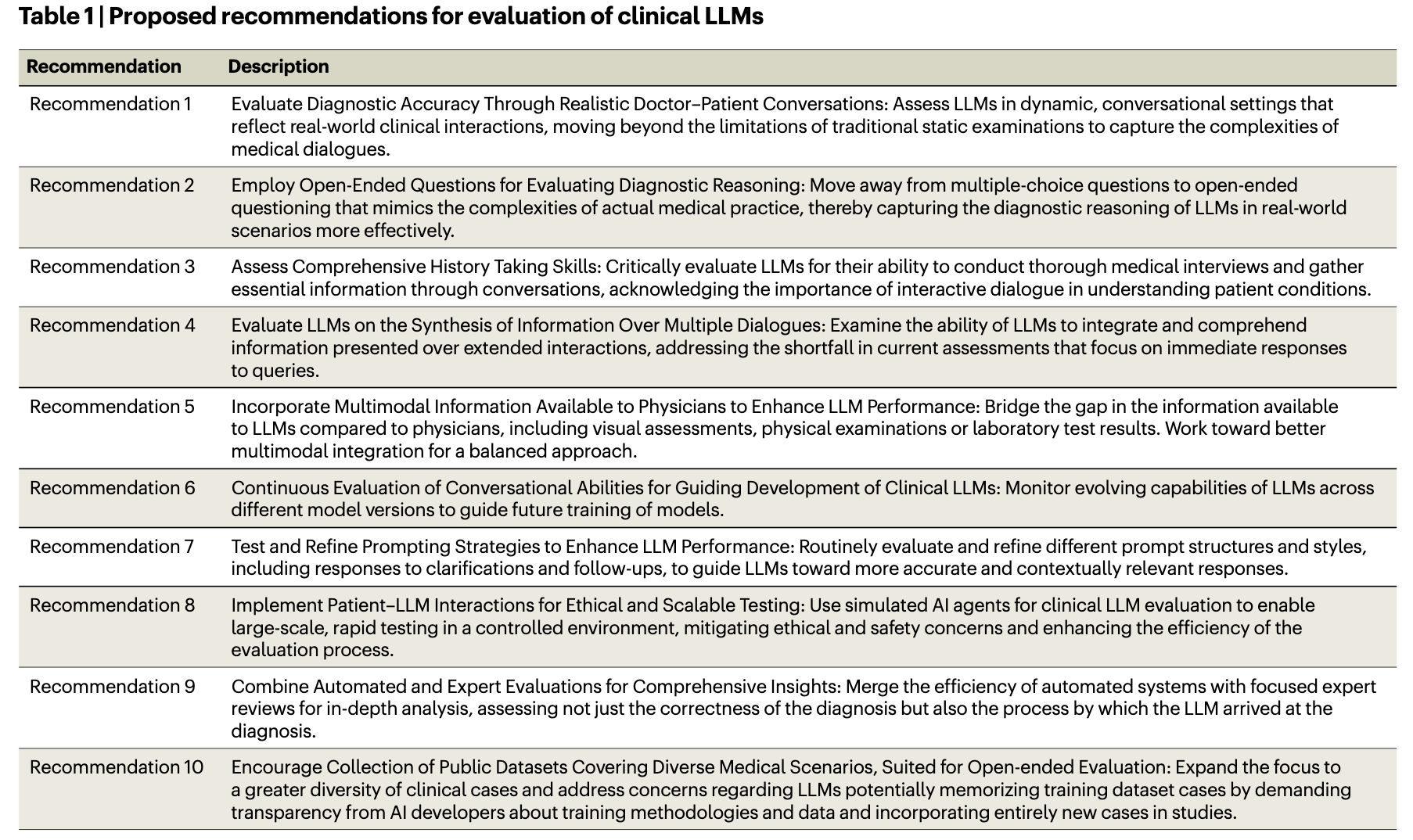
Link to paper, research by Shreya Johori et.al. from the lab of Pranav Rajpurkar
Jan 4, 2025
January 5, 2025
Bayesian Thinking Talk (youtube) #
Talk details from Frank Harrell’s blog - includes slides
This beautiful talk about Bayesian Thinking by Frank Harrell should be essential material for scientists who are trained in frequentist methods. The talk covers the shortcomings of frequentist approaches, but more importantly the paths out of those quagmires are also shown.
Frank discusses his journey to Bayesian stats in this blog post from 2017 which is also in the next section.
Bayesian Clinical Trial Design Course is linked at the end of the talk and happens to also have many good resources.
- There is probably sufficient material here for me to be able to include a dedicated section on Bayes for all my link posts.
My Journey from Frequentist to Bayesian Statistics #
The most useful takeaway for me from this post is that even experienced statisticians had to steer towards Bayes fighting both agains norms and their education.
The post has many many good references to whet your appetite if you are Bayes-curious. I particularly liked the following take:
slightly oversimplified equations to contrast frequentist and Bayesian inference.
- Frequentist = subjectivity1 + subjectivity2 + objectivity + data + endless arguments about everything
- Bayesian = subjectivity1 + subjectivity3 + objectivity + data + endless arguments about one thing (the prior)
where
subjectivity1 = choice of the data model
subjectivity2 = sample space and how repetitions of the experiment are envisioned, choice of the stopping rule, 1-tailed vs. 2-tailed tests, multiplicity adjustments, …
subjectivity3 = prior distribution
I found Frank’s blog from this page, I went from not knowing who he was to adopting him as a teacher. Maybe you’ll find someone interesting too.
Jan. 3, 2025
January 3, 2025
In 2025, blogs will be the last bastion of the Good Internet #
Erik Hoel writes
a work of maximalism succeeds when it triggers this property in the experiencer. You know that the whole is there, but you can’t see it all at once. You can only take it in sequentially. It is the awareness of an emergent form you, as a limited being with only a periscope for perception, cannot actually understand in full.
And this same reaction of “I don’t even know where to look, or where to begin” in the viewer (here, reader) is what I think the very best of blogging should strive for.
This was the exact reaction I had over 15 years ago when I came across my first real blog, ribbonfarm.com. Around this time blogging came into it’s heyday and many other blogs were found and devoured. The blogs all had this quality defined by the quantity, it was like making a friend without ever meeting the person.
As AI slop (that’s the official term now) takes over and corrodes what was left finding good thing even thorough social media will be difficult. I agree with Erik, blogs being high ownership media will be where we will go to have fun.
Simon Willison’s approach to running a link blog #
Speaking of AI slop, Simon Willison, who coined the term, recently did this beautiful write up about how to post what’s perhaps the simplest kind of blog post, the link post. It is the same thing which you probably do with your friends in your private chats or your hundred channel discords post interesting things write a bit about them.
On the blog side, we can stand on the shoulders of these blogging giants and in the spirit of the internet copy and evolve their best practices. Simon has a longer list in the post that you should read, these bits about how to do it nicely stood out to me:
- I always include the names of the people who created the content I am linking to, if I can figure that out. Credit is really important, and it’s also useful for myself because I can later search for someone’s name and find other interesting things they have created that I linked to in the past. […]
- I try to add something extra. My goal with any link blog post is that if you read both my post and the source material you’ll have an enhanced experience over if you read just the source material itself.
- Ideally I’d like you to take something useful away even if you don’t follow the link itself. This can be a slightly tricky balance: I don’t want to steal attention from the authors and plagiarize their message. Generally I’ll try to find some key idea that’s worth emphasizing. […]
- I’m liberal with quotations. Finding and quoting a paragraph that captures the key theme of a post is a very quick and effective way to summarize it and help people decide if it’s worth reading the whole thing. […]
- If the original author reads my post, I want them to feel good about it. I know from my own experience that often when you publish something online the silence can be deafening. Knowing that someone else read, appreciated, understood and then shared your work can be very pleasant.
- A slightly self-involved concern I have is that I like to prove that I’ve read it. This is more for me than for anyone else: I don’t like to recommend something if I’ve not read that thing myself, and sticking in a detail that shows I read past the first paragraph helps keep me honest about that.
Yes, very meta of me to post this.
AI, Investment Decisions, and Inequality #
[full-text] As a practitioner in the field, I’ve always maintained that AI is a tool on the lines of spreadsheets. It gives superpowers no matter who you are but if you are an expert in your domain the power is multiplicative. Seems actual research, by Eric So and others, is coming to similar conclusions:
We hypothesize that the widening performance gap across investor groups stems from an inherent trade-off–making AI summaries accessible to less sophisticated investors sacrifices technical precision. For example, whereas a simple summary might note “a reduction in profits,” the advanced version specifies “operating margins declined due to higher input costs caused by supply chain disruptions”—creating a gap in the precision of the signals that participants receive. Consistent with this hypothesis, we find that the performance gap between more versus less sophisticated participants widens when more technical information is omitted from the simplistic summaries, such as discussion of R&D spending, share repurchases, and gaps between EBITDA vs. net profits. Thus, the efforts to make financial information more accessible via AI come at the cost of reduced precision, potentially limiting AI’s ability to fully democratize financial decision-making.
While specialization may be for insects, context is for kings (Star Trek) and jargon compresses the progress to circumscribe the exact matter at hand. Those who can compress better not only can judge better but can narrow down the scope of the LLM to get better analysis done. It seems this will also lead to a widening gap rather than a democratization:
Our analysis yields two central results. First, there is a significant improvement in both information processing ability and the quality of investment decisions following AI adoption. However, this effect holds (for both sophisticated and unsophisticated groups of users) as long as AI output is aligned with user sophistication. Second, AI widens the knowledge-driven disparities between sophisticated and unsophisticated participants.
Why probability probably doesn’t exist (but it is useful to act like it does) #
[Paywall version on nature], David Spiegelhalter takes his lifetime of experience to tell us of the church choir why this is a useful fiction.
numerical probability, I will argue — whether in a scientific paper, as part of weather forecasts, predicting the outcome of a sports competition or quantifying a health risk — is not an objective property of the world, but a construction based on personal or collective judgements and (often doubtful) assumptions. Furthermore, in most circumstances, it is not even estimating some underlying ‘true’ quantity. Probability, indeed, can only rarely be said to ‘exist’ at all.
[…]
In the natural world, we can throw in the workings of large collections of gas molecules which, even if following Newtonian physics, obey the laws of statistical mechanics; and genetics, in which the huge complexity of chromosomal selection and recombination gives rise to stable rates of inheritance. It might be reasonable in these limited circumstances to assume a pseudo-objective probability — ‘the’ probability, rather than ‘a’ (subjective) probability.In every other situation in which probabilities are used, however — from broad swathes of science to sports, economics, weather, climate, risk analysis, catastrophe models and so on — it does not make sense to think of our judgements as being estimates of ‘true’ probabilities. These are just situations in which we can attempt to express our personal or collective uncertainty in terms of probabilities, on the basis of our knowledge and judgement.
[…]
we perhaps don’t have to decide whether objective ‘chances’ really exist in the everyday non-quantum world. We can instead take a pragmatic approach. Rather ironically, de Finetti himself provided the most persuasive argument for this approach in his 1931 work on ‘exchangeability’, which resulted in a famous theorem that bears his name. A sequence of events is judged to be exchangeable if our subjective probability for each sequence is unaffected by the order of our observations. De Finetti brilliantly proved that this assumption is mathematically equivalent to acting as if the events are independent, each with some true underlying ‘chance’ of occurring, and that our uncertainty about that unknown chance is expressed by a subjective, epistemic probability distribution. This is remarkable: it shows that, starting from a specific, but purely subjective, expression of convictions, we should act as if events were driven by objective chances.
2025-01-02 Links
January 2, 2025
Are we slowly entering the post data annotation world? #
The act of annotating data for ML has always been a shortcut to access concepts not present in the training data. This new work, incorporates literature with data to achieve a fuller picture with complementary information.
Specifically the tech,
utilizes GPT-4 to induce reliable disease-specific human expert concepts from medical literature and incorporate them with a group of purely learnable concepts to extract complementary knowledge from training data.
The internet is big, actually #
Over a decade ago I heard from researchers that they used twitter as a sort of internet nematode. Since then, I’ve repeated that the population on twitter does not represent the real world much the way works in nematode is far from works in humans.
Katherine Alejandra Cross via Bluesky Won’t Save Us discusses the nature of social media:
Like radiation, social media’s algorithms and network effects are invisible scientific effluence that leaves us both more knowledgeable and more ignorant of the causes of our own afflictions than ever; in turn, this leads to deepening distrust in the experts who are blamed for producing them
And further articulates the actual effect of social media where the very online amplify a signal only they see:
Put simply: staring at the doomscroll isn’t good for anyone, but it’s especiallydangerous for people with power and influence. Perhaps such a harm-reduction approach is more compassionate than an outright ban, weaning overly online journalists and celebrities off of the more dangerous stuff, steadily unplugging them from the Necronomicon of networks no mortal was meant to stare into.
As they used to be called, before they became users, the denizens of the internet, would very much benefit from a return to the old ways of the internet where you built a little corner of your own.
Which brings me to a different post by Chris Holdgraf at How I’m trying to use BlueSky without getting burned again where he acknowledges that platforms are useful but ultimately not places to sink too much into.
I’m going to try treating BlueSky as a temporaryplace to make connections or share ideas, but do my best to direct attention, deeper thoughts, “real” value to places that I have more control over.
We get 6 useful rules to consider and have the mindset of inviting friends over for tea than hanging out at the local global cafe:
- Build your castle on land you own
- Shamelessly use other kingdoms just like they’re using you
- Always move people back to your kingdom, never to another kingdom
- Operate like your castle can get shutdown tomorrow
- Be suspicious of new kingdoms that give away easy visibility
- Give good reasons to go back to the Castle in your Kingdom. And be persistent!
As if she couldn’t be cooler #
via ‘She believed you have to take sides’: How Audrey Hepburn became a secret spy during World War Two
When Allied airmen heading for Germany had to make an emergency landing in the Netherlands, Visser ’t Hooft sent Hepburn to the forest to meet a British paratrooper with code words and a secret message hidden in her sock. She made the meeting, but on the way out of the forest, she saw Dutch police approaching. She bent down to pick wildflowers, then flirtatiously presented them to the police. They were charmed and didn’t interrogate her further. After this, she often carried messages for the resistance.
“She believed very much that there is a struggle between good and evil and you have to take sides,” Dotti says.
2025-01-01 Links
January 2, 2025
Beauty as resistance - Good visualization design is an act of liberation by Alberto Cairo
Good visualization tells the reader what the collected data is saying it creates a little place in an otherwise confusing space.
Truth and liberty are entwined in a self-reinforcing loop. When we design a good visualization we aren’t just conveying our best understanding of a truth; by sharing our contemplation of that truth, we’re also making ourselves and our readers freer.
Data science, statistics, machine learning is creative work its beauty lies in making visible what lies latent in the world.
Work harder, protect others, do good, and create beauty. Camus inspires those words. Your work matters; you matter. Doing ethical, beautiful work—visualization work, or any other creative work—and putting it out there for others to learn, enjoy, and inform themselves to live better lives, imbues a meaningless world with meaning. Any expression of beauty is a rebellion against darkness, a repudiation of ugliness, and an act of resistance against ignorance and malice.